
© 2001
cesi / Pierre-Yves Dupuis
Module de formation ŕ distance
|
|
Introduction aux Systèmes
de Gestion de Bases de Données
Module de formation ŕ distance |
8.2 Interpréter les instructions SQL définissant des jointures entre les tables, les regroupements et la manipulation de données
Requêtes multi-tables : syntaxe de description de jointure
Créons une requête multi-tables et visualisons-la en mode SQL :
 |
 |
|
|
La jointure porte sur deux tables ; elle est exprimée, dans la clause "FROM", par la syntaxe : "<NomTable1> INNER JOIN <NomTable2> ON <NomTable1>.<NomChamp> = <NomTable1>.<NomChamp>" Remarque : Contrairement à ce que l'on a vu dans le chapitre précédent pour la clause SELECT, on ne peut pas se dispenser de répéter les noms des tables dans la clause "ON" de la jointure Voyons maintenant l'utilisation de cette syntaxe dans le
cadre de jointures plus complexes : |
||
 |
||
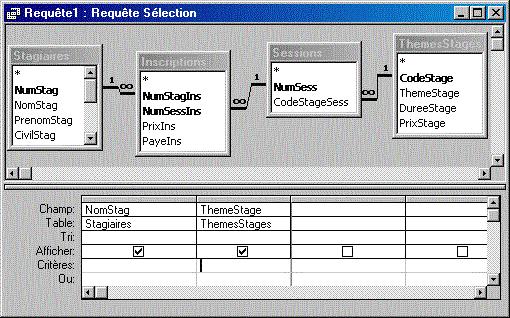
Ici, 3 jointures relient 4 tables ; comment le SQL traduit-il cela dans sa syntaxe ? |
||
 |
||
|
La syntaxe "JOIN" effectue la jointure entre deux tables ; le parenthèsage permet d'utiliser le résultat d'une jointure en le joignant avec une autre table. On pourrait traduire l'expression ainsi : "Stagiaires est jointe avec (résultat de la jointure entre Inscriptions et (résultat de la jointure entre ThèmesStages et Sessions))" |
||
Les requêtes SQL exprimant des jointures entre de nombreuses tables demandent à être "disséquées" pour pouvoir être interprétées ; on constate que pour ce qui est des jointures, le mode création d'Access est plus lisible que la syntaxe SQL.
A noter : La jointure "INNER JOIN" est également appelée "Equijointure" ; il existe d'autres types de jointures qui peuvent être utiles dans certains cas spécifiques. Ceci dépasse le présent cadre d'initiation et serait plutôt l'objet d'un module spécifique sur le SQL.
Regroupements d'enregistrements : GROUP BY et instructions associées
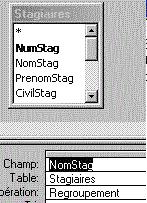
Le regroupement est spécifié en SQL par l'instruction "GROUP BY", suivie de la liste des champs sur lesquels le regroupement doit être fait, séparés par des virgules.
 |
 |
|
Regroupement sur un seul champ
|
|
 |
 |
|
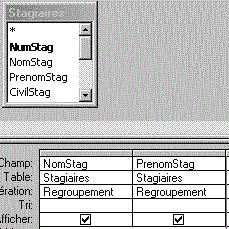
Regroupement sur deux champs : les noms de champs sont
en liste,
séparés par des virgules, après le mot clé "GROUP BY". |
|
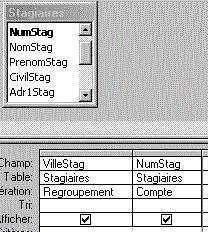
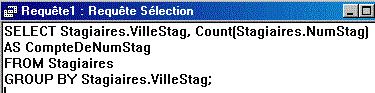
Les fonctions de calcul sur les groupes sont, elles, utilisées dans la clause "SELECT" de la requête ; en voici deux exemples :
 |
 |
|
Comptage sur un groupe ; remarquez qu'automatiquement,
Access a généré une clause "AS" pour renommer
la colonne du comptage
|
|
 |
 |
|
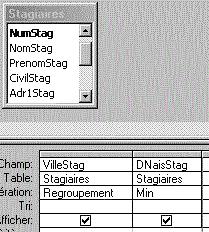
Calcul du "Min" d'un champ
|
|
Relations entre les clauses SELECT et GROUPBY
Lorsqu'une requête comporte une clause GROUPBY, tous les éléments énumérés dans la clause SELECT doivent avoir un rôle défini dans le cadre du regroupement : soit ils sont affectés par une opération de groupe (count, sum, etc.), soit ils servent à regrouper les enregistrements et figurent donc dans la clause GROUPBY. Si vous tentez de définir un champ dans le select sans respecter cette règle, le moteur de base de données ne pourra pas effectuer la requête et vous affichera un message d'erreur.
Critères avec GROUPBY
Requêtes action
Les requêtes de manipulation de données (appelées "Requêtes action" par Access) correspondent à des types de requêtes différents. Le mot clé "SELECT" est ici remplacé par un mot clé représentant l'action que la requête va effectuer lors de son exécution ; voici les traductions SQL des requêtes action que nous avons étudiées dans l'unité d'apprentissage n° 6.
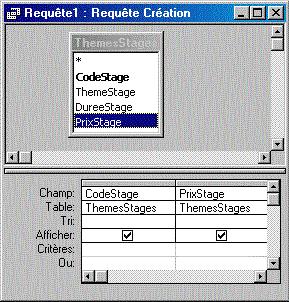
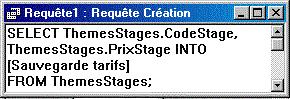
Requêtes "création de table" : "SELECT ... INTO"
 |
 |
|
Le mot-clé "INTO", qui suit la liste des champs, précède le nom de la nouvelle table. Access a placé des crochets autour de ce nom, car il comporte un espace. |
|
Requêtes "ajout" : "INSERT INTO"
 |
 |
| Les mots clé "INSERT INTO" sont immédiatement suivis du nom de la table, puis de la liste des champs qui vont être remplis. La Partie "SELECT" de l'instruction définit les champs dont les valeurs vont être utilisées. Les deux listes de champs de l'"INSERT INTO" et du "SELECT" doivent avoir un ordre concordant, car c'est cet ordre de déclaration qui déterminera les correspondances entre les champs. | |
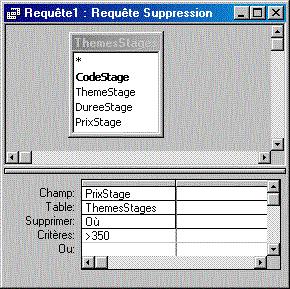
Requêtes "suppression" : "DELETE"
 |
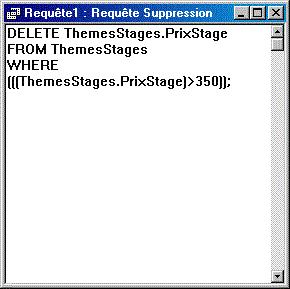 |
| Le nom du champ qui suit le mot clé "DELETE" importe peu : ce sont de toutes façons les enregistrments en totalité qui seront supprimés (habituellement, en SQL, on fait figurer l'étoile "*"). La suppression des enregistrements est ici conditionnée au critère formulé sur le champ "PrixStage". | |
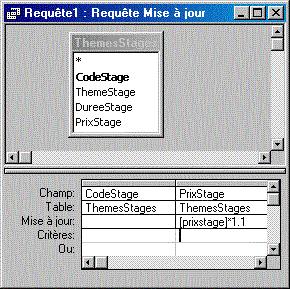
Requêtes "Mise à jour" : "UPDATE"
 |
 |
|||
|
Une requête "UPDATE" met à jour les champs qui sont cités dans la partie "SET" de l'expression. Si plusieurs champs doivent être mis à jour, la forme syntaxique est la suivante : SET Champ1 = Expression1, Champ2 = Expression2, Champ3 = Expression3...
|
||||
|
|
